
はじめに|Excelだけでの集計、ちょっと限界感じてませんか?
広告代理店でメディアプランナーとして働いている私は、媒体別の広告予算に対して、想定されるリーチ率を日々計算し、社内外にレポートを作成していました。
しかし、Excelでこの作業をやろうとすると、以下のような壁にぶつかりました:
- 大量のデータ処理が重くて動作が遅い
- 表をいじるたびに関数がズレる
- 変数ごとの相関や分布を見るのがめちゃくちゃ面倒
この時、「一度コードを書いてしまえば、以降はデータ更新だけでOK」というPythonの魅力に出会い、Pandasを使い始めたのがきっかけです。
本記事のゴール
本記事では、Pandasを使ってCSVファイルを読み込み、以下のような よく使う基本操作8選 を通じて、実務の集計作業がどれほど効率化できるかを解説します。
よく使うPandasの基本操作7選
ここからは、僕が実務でよく使う7つの操作を具体例とともに紹介します!
Step0|どんなCSVを使うの?
まずは、以下のようなCSVを想定します。
📄 CSVデータの構造(例)
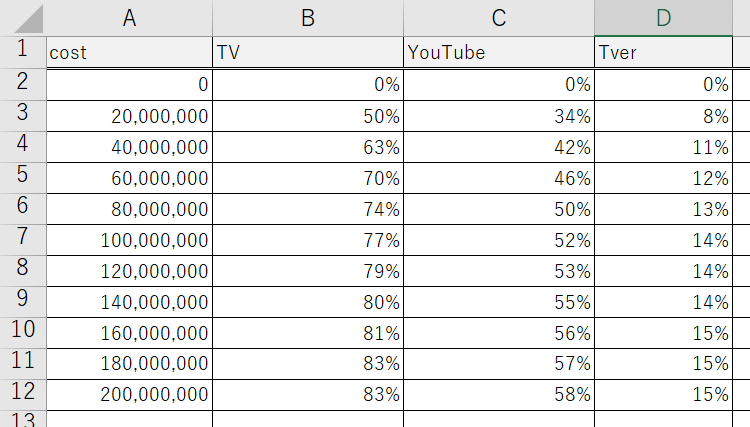
【A列】:広告予算
【B~D列】:各媒体のリーチ率を示したデータです!
きっと、Excelで見慣れたデータですよね。
今回活用するcsvファイルは以下からダウンロード可能です!👇
このデータをPythonに読み込み、一括集計&抽出することで、
「予算に応じてどの媒体のリーチ率が効率的か」をすばやく可視化し、
媒体別の割り振りシミュレーションに活用しました。
Excelでもできないことはないですが、
Pythonなら元データが変わっても再実行で一発更新。
これが、業務効率化の鍵でした。
Step1|CSVを読み込む(read_csv)
では、実際にcsvファイルをPythonに読み込ませていきます。
以下のコードをPythonに打ち込んでください。
import pandas as pd
# CSVの読み込み
df = pd.read_csv("media_reach.csv")
print(df.head())
※「csvファイルが読み込めない」という方は以下の記事を参考にしてみてください。
【初心者向け】PandasでCSVが読み込めないときの原因と対処法
📌 ここがポイント:
Pandasのread_csv()を使えば、表形式のデータをそのままPythonで扱えます。
Google Colab上でもアップロード→読み込みでOKです。
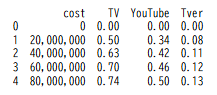
ちなみに、print(df.head())を打つと
こんなグラフが出力されました。
Step2|特定の列だけを取り出す
打つべきコードはたったのこれだけ。
df[["cost","YouTube"]]
→ 任意の媒体データだけを取り出して、絞り込んだ分析や可視化に使えます。
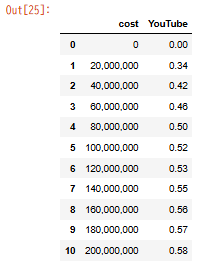
実行ボタンを押すと以下のようなグラフが出力されました。
成功です。
Step3|条件でフィルターをかける
こちらもコードはたったこれだけ。
df[df["TV"] > 0.7]
→ 「TVのリーチ率が70%以上のケースだけを見たい」など、条件を満たす行だけを抽出できます。
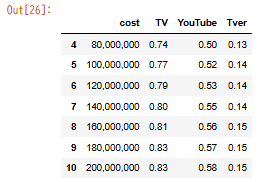
実行ボタンを押すと以下のようなグラフが出力されました。
成功です。
Step4|列の平均・合計を求める
df[["TV", "YouTube", "TVer"]].mean() df[["TV", "YouTube", "TVer"]].sum()
→ 媒体別の平均リーチ率や、合計リーチ率の目安を算出できます。

ちなみに、合計(sum)の場合は
以下のようなグラフが出力されました。
成功です。
Step5|行や列の名前を変更する
df.rename(columns={'cost': 'Budget'})
→ プレゼンや資料化の際にラベルを見やすくするために使います。
csvファイルのラベルが日本語表記だとPythonがうまく回らないことも。
そんな時、このrename関数で一発で英語表記に直すことができるよ!
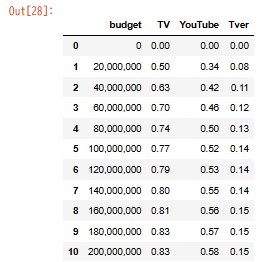
元々「cost」と表記していたグループ名が、「budget」に変更されてますね。
成功です。
Step6|データの並び替え
df.sort_values("TVer", ascending=False)
→ 「リーチ率が高い順」「予算が少ない順」など、意思決定を支える見せ方ができます。
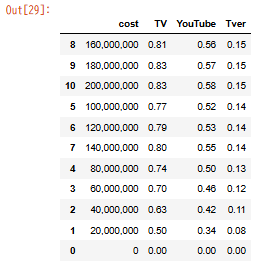
ちなみに、TVerのリーチ率が高い順に並び替えたいの場合は以下のようなグラフが出力されました。
成功です。
Step7|新しい指標(列)を追加する
df["YouTube-efficiency"] = df["YouTube"] / df["cost"] print(df[["cost", "YouTube", "YouTube-efficiency"]])
→ このコードはリーチ率を広告費で割ることで「1円あたりのリーチ効率」を算出したものですが、
複数媒体の合計リーチなど、独自のKPI計算もワンライナーで可能です。
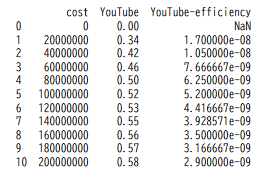
実行ボタンを押すと以下のようなグラフが出力されました。
成功です。
Step8|データをCSVで書き出す(結果保存)
df.to_csv("output.csv", index=False)
→ 結果をExcelに戻したり、クライアント共有用データとして活用できます。
まとめ:単純作業を一瞬で終わらせる武器、それがPandas
実務では、CSVを元にした「集計・抽出・再集計」は日常茶飯事です。
Pandasを使えば、それらの作業を数行で自動化→再利用→分析に発展させることができます。
しかも、
「一度コードを書いておけば、あとは元データを変えるだけ」で再計算できる。
これが、手間の削減にも説得力の強化にも直結します。
🎯非エンジニアのあなたにとってのメリット
Pandasを使えば、一見手間のかかるExcel集計業務も一瞬で自動化できます。
さらに、同じコードを使い回せるため、分析の再現性も高く、社内でも頼られる存在になれるはずです。
まずは1行ずつ、ゆっくりコピペで試してみてください。
あなたの業務が確実に一歩ラクになります。
面倒な集計や単純作業を“定型化”して、考えるべきところに時間を割けるようになる。
Pandasはまさに、そんな武器です。


コメント