
はじめに:Excelでは手が回らない“分析の壁”を感じたことはありませんか?
広告配信キャンペーンの後、配信結果をまとめることはよくありますよね。
- CVRやCV数、imp数などの数値
- 意識調査の結果などの定性データ
- 媒体別、属性別、時系列の集計…
これらをExcelだけで相関を見たり、傾向をグラフ化したりするのって結構ツライと感じたことはないでしょうか?
僕自身、数十列にわたる配信結果や意識調査データを1つずつExcelで見比べていたときに限界を感じ、
「これ、Pythonなら一気にできるのでは?」と思ったのがPandas導入のきっかけでした。
Pandas×可視化が“できるマーケター”感を出せる理由
Pandasは、Pythonで表データ(= Excelみたいな構造)を扱うためのライブラリです。
- 集計/並べ替え/条件抽出が超簡単
matplotlibやseabornと組み合わせれば、数行でグラフが描ける- データ更新も再実行も一瞬なので「繰り返し分析」に強い
さらに、
「このデータをベースに、将来的により高度な分析(共分散構造分析など)に発展させたい」
と思ったとき、Excelでは限界がありますが、Pythonならその先の世界も見えます。
実務で使ってみた:配信結果×意識調査データの“重いExcel”をサクッと可視化
あるクライアント案件で、
CVRやimp、調査データが詰まった巨大なExcelファイルを渡されたことがありました。
最初は相関分析から入ろうと思ったのですが、
「この変数同士、1個1個手動で…?」と思った瞬間に萎えました。
そこでPandasでCSVとして取り込み、数行のコードで一括で相関/グラフを出す設計に変えたんです。
しかも、分析の切り口を増やしたくなったときも、
ネットでコードを調べてコピペするだけで共分散構造分析に発展できた。
結果として、
- 提案に“根拠”が生まれて説得力が上がる
- 時間がかからず、再利用もできる
- 社内で「あの人はプログラミングもできる人」と認識される(笑)
業務効率+ケイパビリティUPの両方が得られました。
CSVデータ×Pandasでの基本可視化:3つの実例
csvデータをpandasで可視化するための事例を3つご紹介します。
※「pandasを使える環境がない」という方は以下の記事を参考にサクッと準備しちゃってください。
【超初心者向け】5秒でできるPython環境構築ガイド【Google Colab編】
🧰 必須ライブラリ(共通)
Pythonを書き始める準備できたら、以下のコードを入力してください。
これは、ご紹介する3つの実例を実践する上で共通の作業です。
import pandas as pd import matplotlib.pyplot as plt import seaborn as sns
そして、CSVファイルを読み込むコードはこれだけ:
df = pd.read_csv("ファイル名.csv")
Google Colabならファイルアップロード機能で読み込めます。
例①:媒体別CTRを棒グラフにする
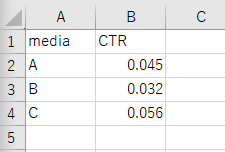
今回はこのようなcsvファイルをPythonに読み込ませます。
Pythonで入力するコードは以下。
df.plot.bar(x='media',y='CTR')
plt.ylabel('CTR')
plt.show()
これだけです。
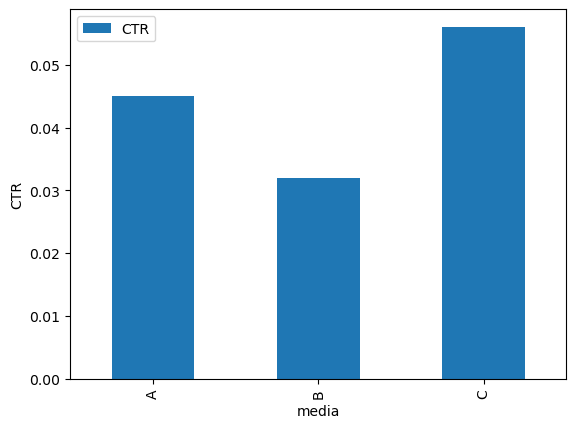
実行ボタンを押すと以下のようなグラフが出力されました。
成功です。
📌 活用場面: 複数媒体の配信結果を棒グラフで1画面で比較するときに◎
例②:日別CVRの推移を折れ線グラフに
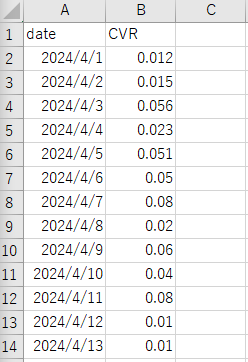
続いて、このようなcsvファイルをPythonに読み込ませます。
Pythonで入力するコードは以下。
# 日付型に変換
df['date'] = pd.to_datetime(df['date'])
df.plot(x='date',y='CVR',marker='o')
plt.ylabel('CVR')
plt.show()
これだけです。
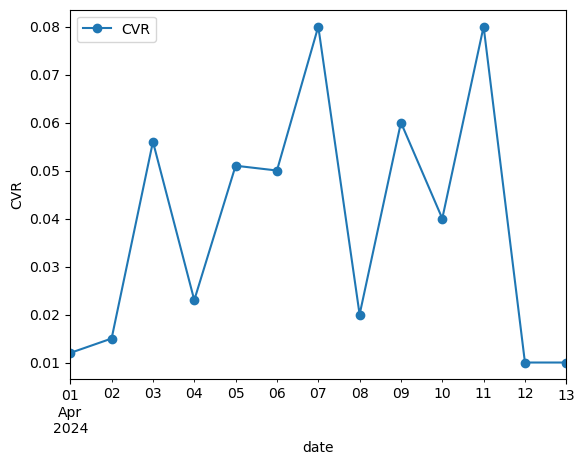
実行ボタンを押すと以下のようなグラフが出力されました。
成功です。
📌 活用場面: 改善施策の効果が“どう推移しているか”を直感的に示すときに◎
例③:ヒートマップで相関関係を直感的に捉える
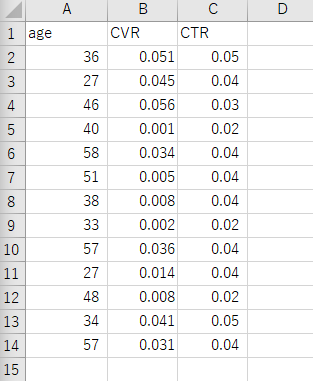
続いて、
このようなcsvファイルをPythonに読み込ませます。
Pythonで入力するコードは以下。
#相関行列を生成 corr = df.corr() #ヒートマップで可視化 sns.heatmap(corr, cmap='coolwarm') plt.show()
これだけです。
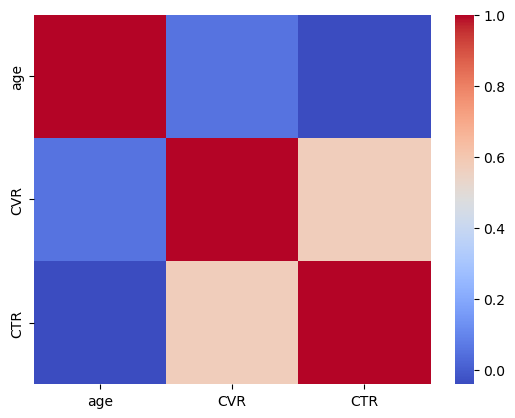
実行ボタンを押すと以下のようなグラフが出力されました。
成功です。
📌 活用場面: 多変数の関係性を一気に見たいとき。分析フェーズの最初に便利!
「え、自分が自動化なんて…」と思ったあなたへ
僕も文系出身で、最初は「Python?ムリムリ…」と思ってました。
でも実際にやってみると、
最初のひな形(コード)だけ押さえれば、あとは“貼って動かす”で何とかなる。
毎回同じようなレポートを作るなら、
- データを差し替えるだけで更新できるし、
- むしろ「地味にすごい人」扱いされることもあります(笑)
だからこそ、同じ悩みを持つ人には強くおすすめしたいんです。
まとめ:CSV1枚と数行のコードで、仕事が変わる
- Excelで限界を感じたら、Pandasを試す価値あり
- 表データ→グラフ化まで5行で完了
- 可視化は「提案の見せ方」だけでなく「分析の第一歩」でもある
まずは手元のCSVファイル1枚で、Pandasを動かしてみてください。


コメント