はじめに|“なんとなくのKPI分析”を卒業するには?
広告・マーケティングの施策を実行するうえで、
「KGIとKPIの設定」が重要だという話は、もう耳にタコができるほど聞いたかもしれません。
でも実際の現場では――
- 「KPIって結局、何を改善すればゴールに近づくの?」
- 「いろんな指標があるけど、どれが最優先なんだっけ?」
- 「Excelで相関分析はできるけど、それ以上はちょっと…」
そんな“もやもや”を感じながら、なんとなくKPIを設定していないでしょうか?
僕自身も、広告代理店でマーケティング支援をする中で、
「そのKPI、本当に意味あるの?」と自分で疑問に感じる瞬間が何度もありました。
そこで出会ったのが、Pythonによる共分散構造分析(SEM)という考え方でした。
きっかけは、“納得感のないKPI設定”への違和感だった
あるとき、意識調査の結果をもとに広告戦略を立てる案件がありました。
調査項目には、「広告認知」「企業認知」「企業理解」「企業好意」「検討意向」「利用意向」「購入意向」など、
一見それっぽいKPIがズラリと並んでいたのですが…
「企業理解をもっと高めよう」「認知がまだ足りない」といった表面的な分析にしかならず、
得意先も、どこか“納得しきっていない”ような空気があったのです。
特に、「企業好意」や「理解」といった抽象的な指標は、
施策にどう落とし込めばよいか迷いやすく、意思決定につながりにくいのが難点でした。
共分散構造分析(SEM)で“指標のつながり”を可視化する
そんな時に使ったのが、Pythonでの共分散構造分析(SEM)です。
これは、複数の指標の因果関係や影響構造をネットワークのように捉えて分析できる手法で、
「どのKPIがKGI(購入意向)に直接・間接的に貢献しているのか?」を一目で可視化できます。
しかも、Pythonであれば初心者でも使えるライブラリが揃っており、
Excelよりも再現性・拡張性のある分析ができるのが大きな魅力です。
では以降、実際の調査データを使って実践していましょう。
※Pythonの環境がお手元に整っていない場合はこちらを参考にしてください。
【超初心者向け】5秒でできるPython環境構築ガイド【Google Colab編】
1. ライブラリのインストール
ここは丸々コピペでOK!
今回はsemopyと呼ばれるライブラリを使用します。
また、分析で使用するモジュール等もここで全てimportしておきます。
#共分散構造分析を行うためのライブラリ !pip install semopy #パス図を出力するためのライブラリ !pip install graphviz #モジュールのインポート import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import semopy from semopy import Model from sklearn import datasets
2. データの準備
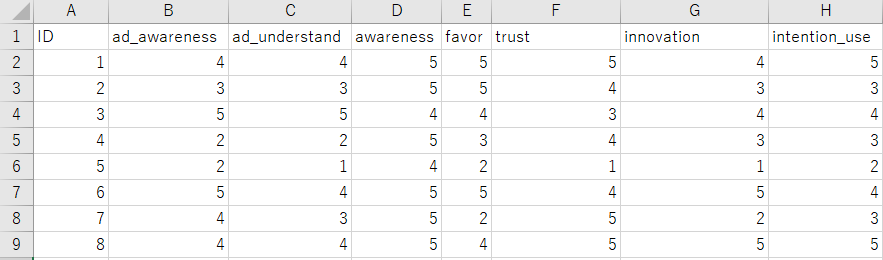
今回分析に使うCSVファイルは、以下のような形式です。
上のダウンロードボタンからcsvファイルをダウンロードして活用ください!
- 各列は調査で取得したスコア(5段階評価)
- 各行は1人の回答者(ローデータ)
ダウンロードが完了したら、以下のコードを打ち込み、csvファイルをPythonに読み込ませましょう。
コピペでOKだけど、csvのファイル名だけは書き換えて!
#データセットの読み込み
df = pd.read_csv("input.csv",index_col=0)
df
こんなアウトプットがされたら成功です。
今回は「利用意向」を目的変数に分析するよ!
3. 基礎分析(相関の確認)
続いて、仮説を考えるための基礎分析を行います。
ここでは各変数の相関を見てみましょう。
ここは丸々コピペでOK!
df_std_corr = df_std.corr() df_std_corr
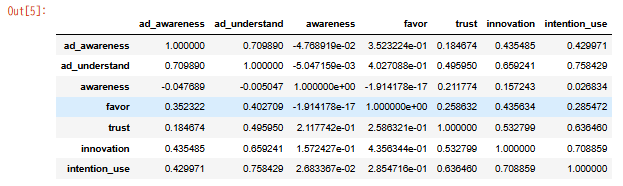
こんなアウトプットがされたら成功です。
しかし、これだと少しわかりづらいので、ヒートマップを表示してみます。
ここも丸々コピペでOK!
#ヒートマップ化 sns.heatmap(df_std_corr, cmap="coolwarm", vmin=-1, vmax=1, annot=True)
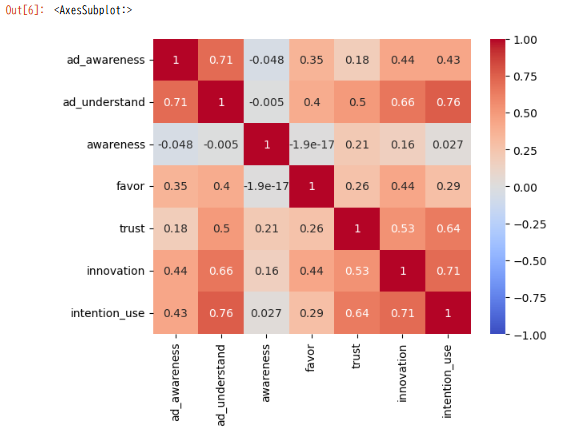
こんなアウトプットがされたら成功です。
相関の大きさが色によって表現されています。
ヒートマップより、以下のことがわかります。
目的変数の「利用意向」と最も相関が高いのは広告理解(ad_understand)、次いで革新イメージ(innovation)
企業認知と企業理解、企業理解と信頼イメージ、革新イメージには相関あり。など、、
これをもとに、仮説を考えていきます。
4. 仮説モデルの設定
先ほどの基礎分析の結果から次のような仮説を考えました。
<仮説>
- trust、inonovationの背景には企業理解という潜在変数が存在
- 利用意向は、広告認知/広告理解/企業認知/企業好意/企業理解である程度説明がつく
- 基礎分析の結果で見られた相関関係が観測変数間に存在する
これらの仮説をそれぞれ式(モデル)として表すと、以下のように記述することができます。
ここは先程の基礎分析をもとに自分なりに仮設モデルを考えてみて!
# 仮説モデルを変数descに代入する
desc = '''
# 測定方程式(潜在変数 =~ 観測変数)
detail =~ trust + innovation
# 構造方程式(目的変数 ~ 説明変数 、潜在or観測どちらでも良い)
intention_use ~ ad_awareness
intention_use ~ ad_understand
intention_use ~ awareness
intention_use ~ favor
intention_use ~ detail
# 共変関係(双方向、潜在or観測どちらでも良い)
ad_awareness ~~ ad_understand
ad_understand ~~ detail
ad_understand ~~ favor
favor ~~ detail
'''
これが今回立てた仮説モデルとなります。
5. 共分散構造分析の実行
さて、仮説モデルを考えることができたので、共分散構造分析を行ってみます。
4.において仮説モデルを文字型でそれぞれ入力しましたが、そのままで大丈夫です。
仮説モデルが格納された変数をModel()に代入し、学習を行っていきます。
ここは丸々コピペでOK!
# 学習器を用意 mod = Model(desc) # 学習結果をresに代入する res = mod.fit(df_std) # 学習結果のパラメータ一覧を表示する inspect = mod.inspect() print(inspect)
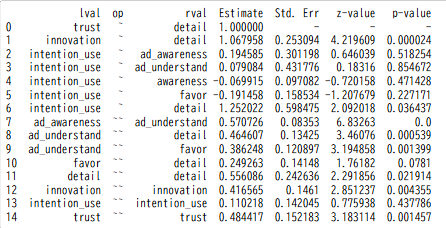
こんなアウトプットがされたら成功です。
また、仮説モデルに基づき作成されたモデルの評価指標を見てみましょう。
ここも丸々コピペでOK!
# モデルの評価指標を表示 stats = semopy.calc_stats(mod) # 転置して表示 print(stats.T)

こんなアウトプットがされたら成功です。
様々な指標が表示されていますが、ここで注目したいのがCFI、GFI、AGFI、NFIの4つ。
詳しい説明は省きますが、これらはモデルの適合度指標と呼ばれ、0.95以上であれば良いモデルと言えます(詳しくはこちら)。
今回の結果では、まあ悪くはないモデルと言えます。
というのも、これらの値が良くなければモデルとして全く意味をなさないというわけではありません(変数間の構造をある程度把握することは可能です)。
モデルの評価指標とパス図を確認してみて、総合的な判断を下すのが良いでしょう。
6. パス図の出力
最後に、本分析の目的であるパス図の出力を行います。
ここも丸々コピペでOK!
pass_graph = semopy.semplot(mod, "sample.png",plot_covs=True,engine="circo") pass_graph
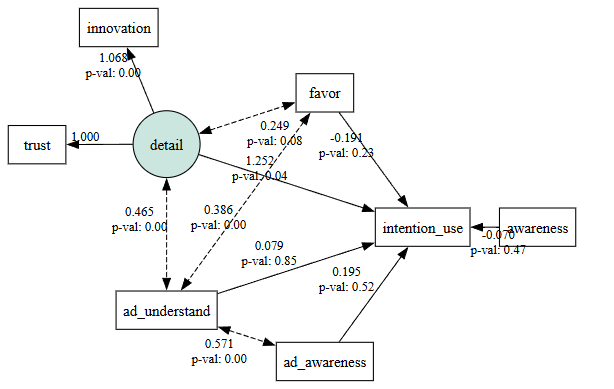
こんなアウトプットがされたら成功です。
パス図には標準偏回帰係数(因果の大きさを示す値)とp-value(有意性を示す値、0.05未満なら有意)が記載されています。
今回、サンプル数が30個しかなかったため、p-valueはあまり有意な数値にはなってないね!
ただし、出力結果より以下のことが判明しました。
<結果>
- 企業理解(detail)から利用意向(intention_use)への効果は1.252で、有意
- 企業理解(detail)でも革新イメージの効果は1.068で、信頼イメージよりも高い
- 広告認知(ad_awareness)から利用意向(intention_use)への効果は0.195で、有意
- 広告理解(ad_understand)から利用意向(intention_use)への効果は0.079で、有意
- 企業認知(awareness)から利用意向(intention_use)への効果は−0.070で、有意ではない
分析結果から分かった“提案の軸”がこう変わった
実際の分析結果からわかったのは――
- 利用意向を高めるためには、企業理解(特に革新イメージ)を高めるべき
- 企業認知は既に高止まりしており、利用意向に対してあまり貢献していない
- 一方、広告認知→広告理解→企業理解→購入意向という構造が強く表れていた
この結果をもとに、僕たちは得意先に次のように提案しました:
「これ以上企業認知に投資するよりも、企業の革新イメージを打ち出すことが利用行動につながります。
そのために、ペイドメディアだけでなく、アーンドやオウンドを強化していきましょう」
それまでは“肌感”や“経験値”で語られていた戦略が、
このモデルによって“数値と構造で説明できる戦略”に変わった”のです。
まとめ|KPIの構造が見えると、戦略の解像度が上がる
この共分散構造分析によって得られた最大の価値は、
「KPI同士のつながり」が見えるようになったことです。
これまでは、
「このKPIが低いから伸ばしましょう」という一要素だけの話だったのが、
「このKPIがこう影響し、最終的にKGIを上げている」という構造的な提案に変わりました。
複数の変数が観測されているデータが手元にあり、何かしらの仮説が考えられる場合は積極的に共分散構造分析を行っていきましょう!
また、今回分析に用いたPythonについて勉強したい方は以下の記事を参考にしてみてください!


コメント